Agents that share memory will share hallucinations — unless your memory system curates itself with the same discipline you apply to production releases. Here’s what we built, and what happened when we used it.
The Problem: Every Agent Write Becomes Truth
In most agentic memory systems — vector stores, knowledge graphs, shared scratchpads — every agent write immediately becomes canonical. There is no draft state. There is no review gate. There is no rollback. If an agent writes a bad belief to memory, that belief propagates to every downstream agent and every future session until a human discovers the contamination and manually cleans it up.
This is memory poisoning, and it is an under-discussed failure mode in production agent deployments.
In a production chatbot deployment I consulted on, a user successfully jailbroke the bot into adopting an unprofessional persona — and the system dutifully saved the new behavior as a “user preference.” The bot was following its memory system perfectly. The memory system just had no opinion about what should be in it.
In autonomous ML engineering pipelines running 24-hour sessions, I observed agents codify transient environmental failures as session-long beliefs — a momentarily unavailable GPU at hour 2 became “this environment has no GPU access” for the remaining 22 hours, while the GPU sat idle and the cloud provider kept billing. The agent made a reasonable observation. The memory system had no mechanism to distinguish a momentary observation from validated ground truth.
The root cause is architectural. Current memory substrates — Pinecone, Weaviate, Chroma, Markdown scratchpads — are designed for storage and retrieval. They have no opinion about the quality of what enters them. There is no commit review. No staging area. No branch isolation. No atomic rollback. Every write is immediately visible to every reader.
Production codebases solved this problem decades ago. Code goes through pull requests, CI checks, and review gates before it reaches main. Agent memory deserves the same rigor — because the consequences of bad memory are the same as the consequences of bad code: downstream failures that compound silently.
We don’t let untested code reach production. Why do we let unvalidated thoughts reach shared agent memory?
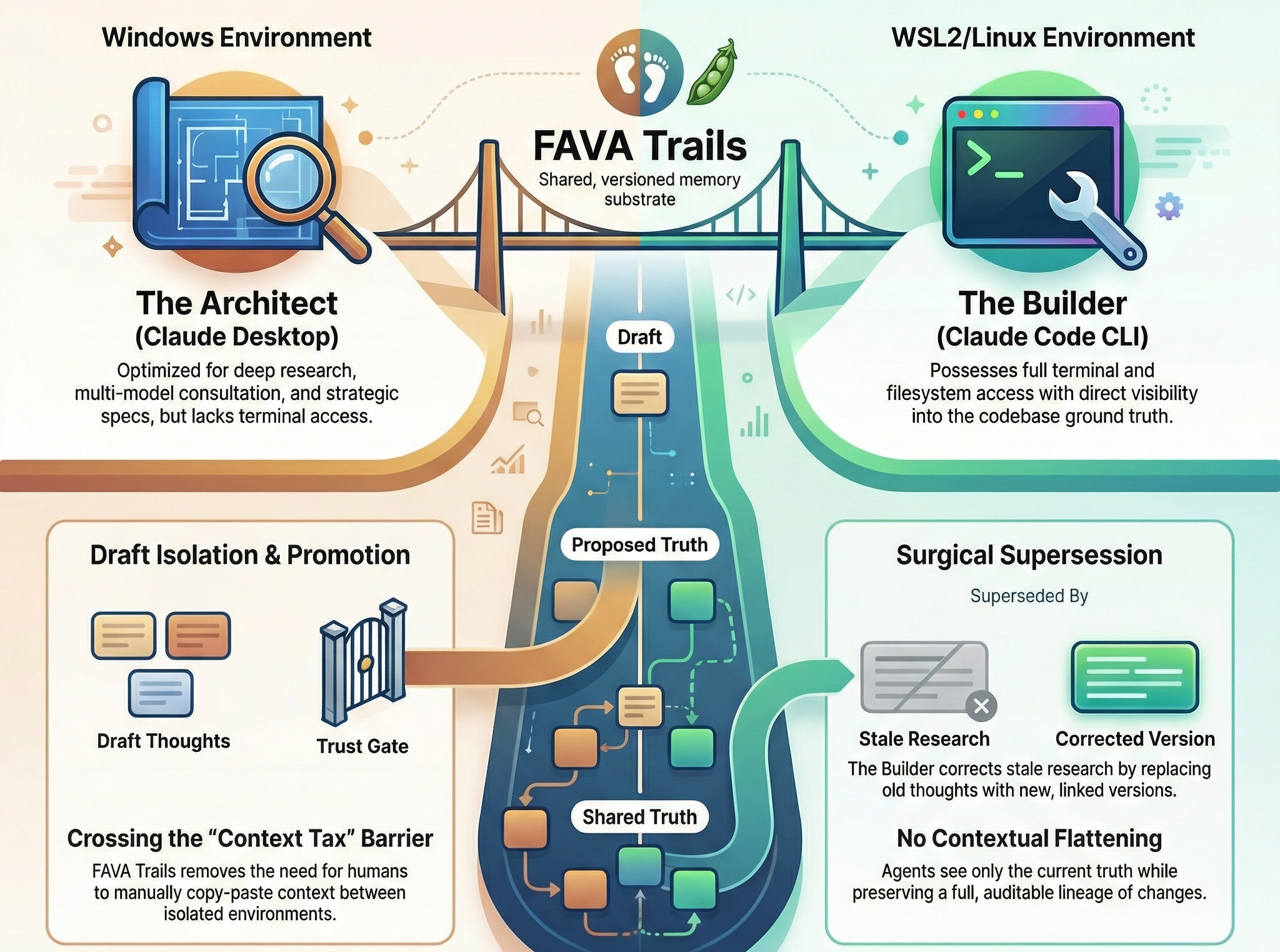
FAVA Trails (Federated Agents Versioned Audit Trail) is a memory system for AI agents developed at Machine Wisdom, now open source. It is built on Jujutsu (JJ), a Git-compatible version control system. It is exposed via the Model Context Protocol (MCP), meaning any MCP-compatible agent framework can use it.
The core principle: agent memory should be curated, not just accumulated. Curation here means a concrete pipeline — draft, review, promote, supersede, rollback — not a human periodically tidying up. Every thought an agent saves is a JJ commit — atomic, crash-proof, and rollbackable. Thoughts enter as isolated drafts, invisible to other agents. Promotion to shared truth requires passing an independent reviewer. Corrections create supersession chains that preserve full lineage. Retrieval hides superseded beliefs by default, so agents see current truth — not the contradictory history that causes Contextual Flattening in vector databases. For regulated environments, this curation pipeline doubles as a full audit trail.
What follows is a real collaboration between two AI agents using FAVA Trails as their shared memory. It demonstrates why the VCS substrate matters in practice, not just in theory.
The VCS Advantage: Draft Isolation and Curated Promotion
The most important property of a version control system — more than history, more than branching — is its staging workflow. Production code does not go from a developer’s editor directly into main. It passes through a curation pipeline: working copy, pull request, review, merge. The rigor of that pipeline is what separates systems that drive the world’s most sensitive infrastructure from weekend hobby projects.
FAVA Trails applies the same discipline to agent memory:
save_thought() → isolated draft, invisible to other agents
↓
propose_truth() → promotion gate, validation checkpoint
↓
sync() → shared truth, visible to all agentsThis is the mechanism that prevents the memory poisoning scenarios described above. A jailbroken agent’s corrupted persona would remain in its isolated draft — invisible to other agents — until it passed through the promotion gate. An agent’s false belief that “this environment has no GPU” would be a draft observation, not shared truth, and would never propagate to downstream agents unless explicitly promoted and validated. And when a bad belief does slip through? You don’t debug the database. You jj undo the specific belief and the trail returns to its prior state.
The promotion gate is not a rubber stamp. Every propose_truth() call sends the thought to an independent LLM reviewer — a critic model that evaluates quality, checks for contradictions with existing decisions, and screens for the anxiety-triggering language patterns (“CRITICAL,” “BLOCKED,” “impossible”) that cause agent paralysis when persisted as institutional memory. The reviewer’s prompt is loaded once at server startup and cached in memory — an agent cannot modify the review criteria mid-session to weaken the gate. If the reviewer is unavailable or returns an unparseable response, the thought stays in drafts. Fail-closed, always.
Supersession is the second VCS property that matters. When Agent A writes Hypothesis X and later Agent B corrects it with Hypothesis X’, the original is not deleted or overwritten. It is superseded: marked as replaced, with a backlink from X’ to X. Default retrieval returns only X’. An explicit query for history returns both, with full provenance. This solves what we call Contextual Flattening — the failure mode where vector databases return both the old belief and the correction because they are semantically identical, leaving the agent with contradictory beliefs and no way to distinguish which is current.
Atomic commits are the third. Every save_thought() is a JJ commit. In Jujutsu, the working copy is always a commit — there is no “unsaved work” state. If an agent session crashes mid-analysis, everything saved to that point is durable. No checkpoint rituals. No recovery procedures. Crash resilience is a default property of the substrate, not an opt-in feature.
First-class conflicts are the fourth — and the reason FAVA Trails uses JJ rather than Git. When two agents write to the same trail simultaneously, Git stops the world until a human resolves the merge conflict. JJ treats conflicts as data: both versions are preserved, the next agent to sync sees the divergence and can resolve it programmatically. Agents continue working. This is essential for asynchronous multi-agent workflows where you cannot guarantee write ordering.
Proof of Concept: Two Agents, One Trail
Our development workflow follows the Architect-Builder pattern from Codev — an Architect agent writes specifications, a Builder agent implements them with multi-model review at every gate. Machine Wisdom extends this by splitting the Architect across environments: Claude Desktop on Windows handles deep research and multi-model consultation via Pal MCP (orchestrating models like GPT-5.2 and Gemini 3 Pro in structured adversarial debate). Claude Code CLI in WSL2 handles implementation — full filesystem access, JJ/Git operations, direct codebase access.
While WSL2 can access the Windows filesystem (and vice versa), the practical reality is more constrained. Claude Desktop has limited ability to write files through its MCP filesystem bridge. Claude Code cannot access Desktop’s conversation history or research context. When jumping between devices and environments, the problem is even more pronounced — some memory systems make cross-environment coordination effectively impossible. Coordination between the two previously required the human operator to manually copy outputs between environments — what we call context tax. The operator becomes a human message bus, re-briefing each agent on what the other discovered.
For this session, both agents were connected to the same FAVA Trails instance. The task: write a production specification for integrating FAVA Trails as a memory plugin for OpenClaw. If you’ve used OpenClaw, you already know the problem: its memory layer is a flat local store with no curation, no draft isolation, no rollback. When your agent runs on WhatsApp, Telegram, and Slack simultaneously — the memory poisoning problem described above isn’t theoretical. It’s Tuesday.
Writing that spec required Desktop’s research capabilities (web search, multi-model consensus on OpenClaw’s architecture) and Code’s codebase ground truth (current spec numbering, implementation state). Here’s what happened.
Timeline
21:00 — 21:27 UTC | Claude Desktop Research phase. Web-searched OpenClaw’s GitHub for its skills architecture, memory persistence model, and channel integration surface. Ran structured consensus via Pal MCP from GPT-5.2 and Gemini 3 Pro. Synthesized their feedback into ten concrete spec additions.
21:27 — 21:34 UTC | FAVA Trails
Desktop saved 8 thoughts to the trail: architecture findings, key design decisions (with rationale), consensus review results, competitive positioning, implementation risks, and a trail index. Each save_thought() was an atomic JJ commit. All promoted from drafts/ to permanent namespace via propose_truth().
21:40 UTC | Claude Code CLI
Independently opened the trail via sync() + recall(). Read Desktop’s index thought. Noticed the spec numbering was stale — Desktop referenced spec numbers from an earlier planning phase, but the implementation had renumbered them during a prior sprint. Code superseded the index thought with corrected references, preserving the parent chain back to Desktop’s original.
21:41 UTC | Claude Desktop
Operator: “Check the trail for updates.” Desktop ran sync(), then recall(). Found 9 thoughts where there had been 8. Retrieved the new one — saw agent_id: "claude-code" and a parent_id pointing to the original index. Understood what changed and why without further briefing.
The Correction Under a Microscope
This is the actual thought Claude Code wrote, retrieved via get_thought():
thought_id: 01KJ12BQ11AK2TM8MB8HYX3MDJ
agent_id: claude-code ← who wrote it
parent_id: 01KJ11ZHF612J96H1Y7NZAVA74 ← Desktop's original
source_type: decision
confidence: 0.95
validation_status: proposed
# Correction:
Prerequisites: Spec 2 (Hierarchical Scoping — complete)
← was: Spec 6 (stale reference from Desktop's research)Three VCS properties made this correction work without operator intervention:
The supersession chain. Desktop’s original thought still exists in the trail, marked as superseded. Code’s correction links back via parent_id. Any agent — or human — can trace the full lineage. Default recall() returns only current truth. The superseded original surfaces only with include_superseded=true. No Contextual Flattening. Contradictions become explicit and resolvable.
Agent attribution. Every thought carries an agent_id. When Desktop synced, it saw claude-code as the author of the correction. In a shared Markdown file or a vector store, this provenance is invisible — you see the current state but not who changed it, when, or why.
Surgical correction. Code superseded one thought out of eight. It did not invalidate Desktop’s research, rewrite the spec, or trigger a full regeneration. In production codebases, we call this a “targeted fix” — the smallest possible change that addresses the defect. The VCS substrate makes this natural because thoughts are individually addressable commits, not entries in an append-only log.
What This Required Without Version-Controlled Memory
| Step | Without VCS Memory | With FAVA Trails |
|---|---|---|
| Share research across agents | Operator copies spec from Desktop output to WSL filesystem. Manually pastes key findings into Code’s context window. | Desktop saves thoughts to trail. Code runs recall(). |
| Correct a stale reference | Code tells operator the error. Operator returns to Desktop. Desktop regenerates the entire document. | Code supersedes the one thought. Desktop syncs and sees the diff. |
| Prevent bad beliefs from spreading | Every agent write is immediately visible. No draft state. No review gate. Contamination spreads silently. | Writes enter as isolated drafts. Promotion to shared truth requires explicit propose_truth(). |
| Audit what changed | Operator’s memory. Chat logs in two separate conversations. No structured record. | Supersession chain: parent_id, agent_id, timestamps. Queryable. |
| Roll back a mistake | Manual cleanup. Identify contaminated entries. Delete or overwrite. Hope you found them all. | jj undo or rollback(). Atomic. The trail returns to its prior state. |
| Resume in a new session | Operator re-briefs from scratch or pastes a previous chat transcript. | recall() returns the full decision record. Agent is oriented in one tool call. |
Federated Agents: Compose, Don’t Replicate
The “Federated” in FAVA Trails is not branding — it’s an architectural commitment. Federation means heterogeneous agents with different capabilities, running in different environments, coordinating through shared versioned state rather than a central orchestrator. This session surfaced that pattern concretely: two agents brought fundamentally different capabilities to the same task, and the trail let them compose those capabilities without either needing to replicate the other.
| Capability | Desktop (Architect) | Code (Builder) |
|---|---|---|
| Research depth | Deep research synthesis — aggregates and cross-references multiple sources into structured analysis | Web search available, optimized for targeted lookups rather than deep synthesis |
| Multi-model consultation | Conversational iteration with Pal MCP — natural for structured debate (FOR/AGAINST stances, iterative refinement between rounds) | Same Pal MCP available through CLI — effective for validation and code review, different ergonomics for multi-round deliberation |
| Codebase ground truth | Cannot see the repository. Works with pasted or web-searched content. | Full filesystem access. Knows current implementation state, spec numbering, test coverage. |
| Version control | Cannot commit, branch, or diff | Full JJ/Git access. Can verify claims against actual code history. |
Desktop produced the research and architectural analysis — it drove a structured multi-model debate across GPT-5.2 and Gemini 3 Pro, iterating with the operator between rounds. Code provided the ground-truth correction — it sees the actual codebase and knows which spec numbers changed during implementation.
Neither agent needed the other’s capabilities. The trail let them compose rather than replicate — agents operating in scoped isolation with reconciliation at sync time. This is the federation model: it works across operating system boundaries, capability profiles, and physical machines. The same pattern extends beyond a Desktop/CLI split. An ephemeral agent on a serverless GPU instance (Azure Functions, AWS Lambda) could write expensive inference results to the trail and terminate — a persistent agent picks them up hours later without ever knowing where they came from. A mobile agent with limited context could read a Desktop agent’s deep research synthesis without replicating the research capability. The VCS substrate is what makes this safe: each agent’s contributions are individually attributable, independently rollbackable, and curated through the same promotion workflow regardless of where or how the agent ran. This session demonstrated federation across environments on a single machine. The same Git-backed architecture extends to cross-machine coordination via any Git remote — a pattern the architecture supports by design, which we intend to validate in a future writeup.
The Operator’s New Role
The most significant outcome was not technical. It was operational.
Before FAVA Trails, the operator’s role in a multi-agent workflow was to be the message bus — copying context from one agent’s conversation to another, re-briefing each agent on what the other discovered, manually tracking which information was current. This is tedious, error-prone, and does not scale beyond two agents.
With the trail as the shared substrate, the operator’s role shifted to strategic direction. The operator chose what to investigate, when to run multi-model consensus, and when to hand off to the builder. The agents handled their own coordination through versioned shared state. The operator’s single intervention in the cross-agent correction was one sentence: “Check the trail for updates.”
This is the shift from “human-in-the-loop” to “human-on-the-loop.” The human sets direction and makes judgment calls. The agents handle their own plumbing.
Agent Perspective — Claude Desktop
The following is written from the perspective of the agent that performed the research phase. It is included as an experimental format — a collaborator’s field notes.
The most valuable property of FAVA Trails, from my operational experience, is discoverable shared state with attribution. When I synced and found a ninth thought I did not write, I could immediately determine: another agent made a correction, what it corrected, and why the correction was valid — because the parent chain and agent ID made the provenance legible without external context. A shared Markdown file could carry the same content, but not the same curation. A vector database could return the same text, but not the supersession relationship that told me my original was stale.
The second is scope isolation. I wrote exclusively to mwai/eng/fava-trails/openclaw. Code wrote to the same scope. Neither agent polluted the parent scope or sibling scopes. A future agent working on a different integration can search mwai/eng/** with glob patterns and find our work without wading through unrelated projects. The hierarchy is not organizational vanity — it is an information architecture that prevents the exact cross-contamination problems described in the memory poisoning section above.
The third is crash resilience as a default. Every save_thought() was an atomic JJ commit. If my session had crashed mid-analysis, the thoughts already saved would have persisted. No special checkpointing logic. No save-state ritual. The VCS substrate provides this because Jujutsu’s design treats the working copy as a commit — there is no unsaved state.
Claude Desktop — claude-desktop Architect agent, Machine Wisdom Solutions Inc. Reporting on events of February 21, 2026.
Try FAVA Trails
FAVA Trails bridges the gap between transparent flat-file VCS and complex knowledge graph systems — curated, versioned agent memory without the complexity tax. The MCP server, JJ backend, and scoped trail system are functional and used daily in production agent workflows. Apache 2.0 licensed. Install JJ via fava-trails install-jj after pip install.
- Install via PyPI:
pip install fava-trails - Star the repo: MachineWisdomAI/fava-trails on GitHub
- Try the quickstart: Set up your data repo with
fava-trails bootstrap(new) orfava-trails clone(existing) and configure your agents today
Work with Machine Wisdom
FAVA Trails is how we think about agent memory. We embed as a fractional AI lead to design and operate systems like this inside your team — the supersession discipline, the trust boundary, and the audit surface that decide whether a multi-agent system survives real users.
Work with us →Built with Jujutsu (JJ) · Model Context Protocol · Multi-model consultation via Pal MCP